
在处理重复数据时,UNIQUE函数是不可或缺的高效工具,相比手动删除重复项或用数据透视表的繁琐,UNIQUE函数只需一个公式,就能秒得无重复数据,大大提升了办公效率。
一、函数作用
核心作用是提取唯一值(重复内容只留1次,不重复内容全保留),优势很突出:
- 效率高:几百行数据几秒搞定,无需手动筛选删除;
- 动态更新:后续新增数据,公式区域足够时,结果自动同步,不用重输公式。
二、语法解析
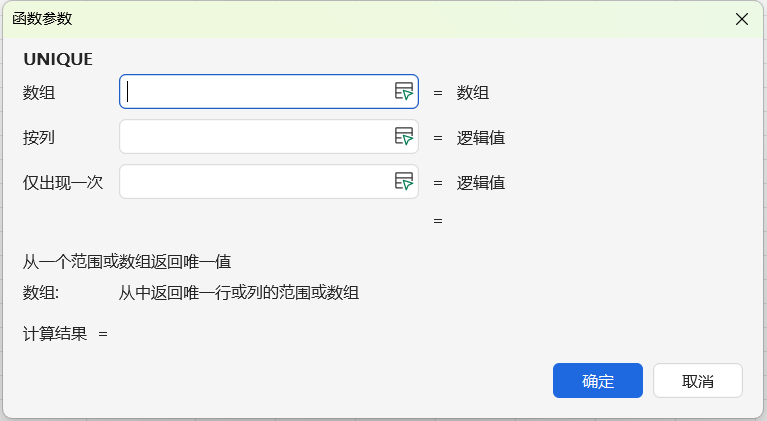
语法:=UNIQUE(数据区域,[是否按列提取],[是否完全重复行])
- [数据区域]是必填项,需要去重的单元格范围;
后两参数可选(默认FALSE):
- [是否按列提取]:TRUE按列去重,FALSE按行去重(日常常用)。
- [是否完全重复行]:TRUE需多列全同才去重,FALSE单列重复即去重(日常常用);
例:单列员工姓名去重,输=UNIQUE(A2:A15),回车秒得无重复名单。
三、实战场景
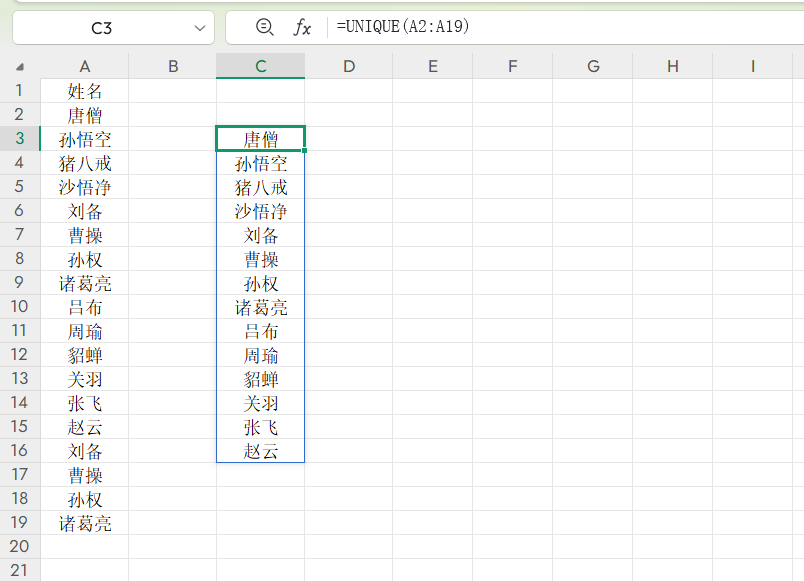
1.单列去重:以考勤表为例,用公式=UNIQUE(A2:A50),直接获取无重复员工名;若想按首字母排序,可以搭配SORT函数=SORT(UNIQUE(A2:A50))。
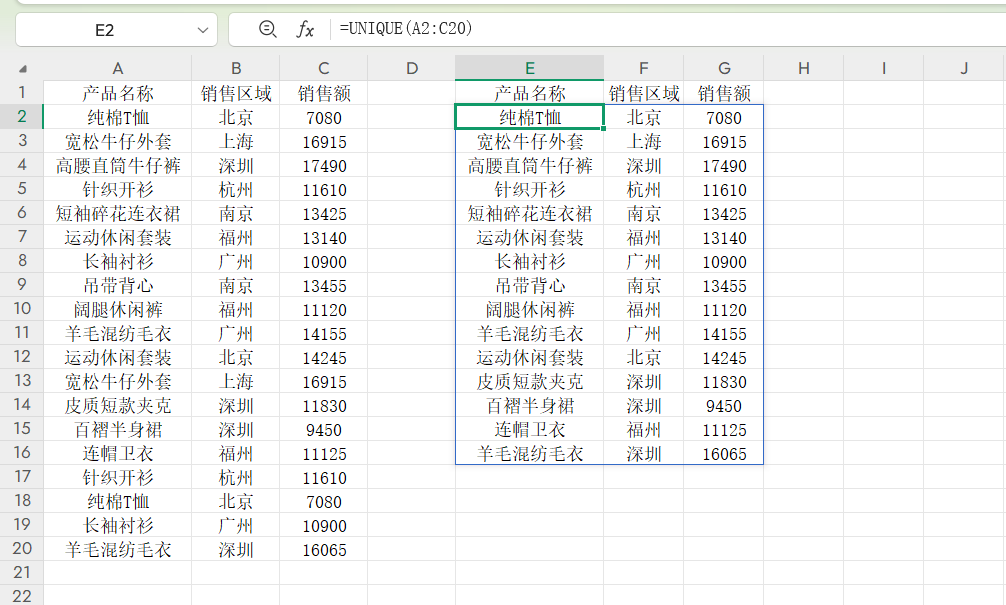
2.多列去重:以销售表为例,若需“产品+区域+销售额”完全一致才去重,公式为=UNIQUE(A2:C20),注意要明确“哪几列组合计算重复”,再确定函数的数据区域,避免结果不符预期。
3.带条件去重:以员工信息表为例,提取技术部不重复员工姓名时,需用UNIQUE搭配FILTER函数先筛选再去重,
公式为=UNIQUE(FILTER(A2:B40,B2:B40="技术部")),回车后会生成技术部无重复的姓名+部门组合,自动排除其他部门数据。
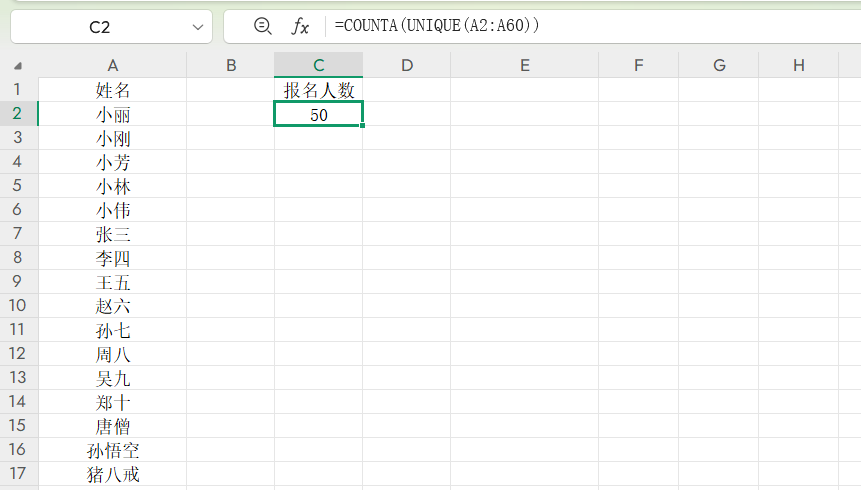
4.统计唯一值数量:以比赛报名表为例,统计实际参赛人数(唯一姓名数量)时,可用COUNTA搭配UNIQUE函数,
公式=COUNTA(UNIQUE(A2:A60)),需注意直接用COUNTA(A2:A60)会包含重复项,结果不准确,需先去重再计数。
四、避坑指南
- #VALUE!错误:数据类型混合了文本和数字导致函数无法识别,选中区域右键“设置单元格格式”,统一设为“文本”再输公式。
- #SPILL!错误:公式旁边有其他数据,导致无法“溢出”生成结果。清空下方/右侧空白区域,结果即可完整显示。
- 数据卡顿:分批去重(如按日期筛本月数据),或去重后复制粘贴为“数值”,删除原公式。
结语
掌握上述UNIQUE函数用法,多数重复数据问题都能快速解决,提升数据处理效率。







评论 (0)