
在数据统计中,处理含文本、逻辑值的总体数据时,精准计算总体标准差是关键需求。STDEVPA函数作为专门应对这类数据的工具,能有效解决非数值数据干扰问题。掌握STDEVPA函数,不仅能避免因数据格式问题导致的统计偏差,还可以让复杂总体数据的离散分析更高效。下面就从基础语法到场景应用,详细讲解STDEVPA函数。
一、STDEVPA函数的核心价值
总体标准差计算的核心痛点,在于非数值数据的处理。比如企业统计员考核绩效时,数据中既有“95”“82”等数值,又有“未考核”(文本)和“TRUE”(逻辑值)。此时STDEVP会直接忽略非数值数据,仅用部分数据计算,结果必然失真;而STDEVPA会将文本视为0、TRUE视为1、FALSE视为0,让所有数据参与运算,真实反映整体情况。
两者的核心差异就在于非数值数据的处理规则:STDEVP仅计算数值,忽略其他;STDEVPA则按固定规则转换非数值数据后纳入计算。因此,纯数值数据用STDEVP更高效,含文本或逻辑值的“复杂数据”必须用STDEVPA。
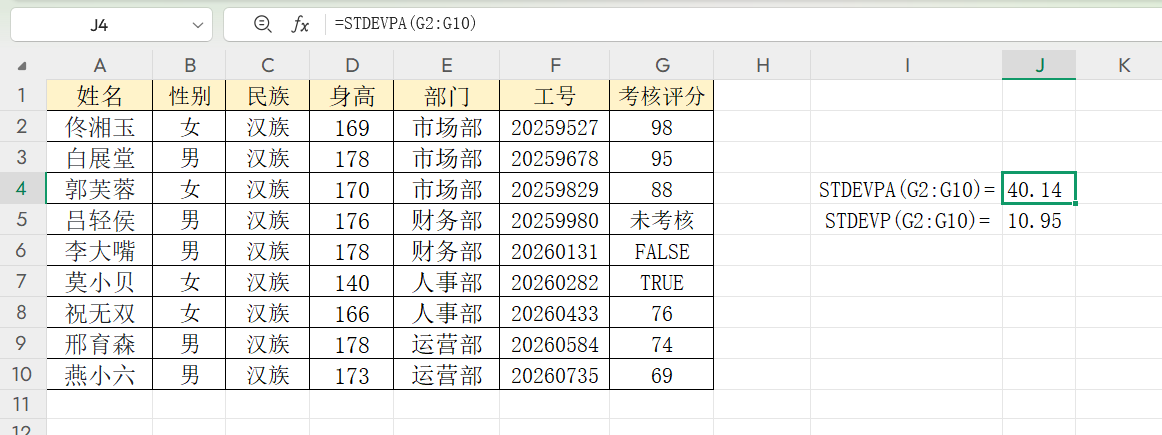
二、STDEVPA函数的基础用法
(1)语法结构
函数格式为“STDEVPA(value1,[value2],...)”。其中value1是必需参数,可输入数值、文本、逻辑值或单元格引用;[value2]及后续为可选参数,最多支持254个数据。
(2)数据处理规则
- 数值:直接参与计算(如“90”“85.5”);
- 文本:无论内容是“未达标”还是空格,均视为0;
- 逻辑值:TRUE按1计算,FALSE按0计算;
- 空白单元格:直接忽略,不参与运算。
需特别注意:空白单元格与文本是完全不同的概念。例如A1为空时不参与计算,A2输入“”(空格文本)则按0计算,两者对结果的影响截然不同。
(3)实操步骤
若需计算A1:A50区域的总体标准差,只需选中结果单元格,输入“=STDEVPA(A1:A50)”,系统会自动转换区域内的非数值数据,瞬间得出结果。
三、STDEVPA函数的实战应用场景
(1)人力资源:全员绩效波动分析
某公司100名员工中,10人标记“未考核”、5人标记“TRUE”(超额完成)。用STDEVPA计算后,若标准差为12分(平均分75分),说明多数人绩效在63-87分之间,整体波动小;若标准差达25分,则需重点关注低分和未考核员工。
(2)教育领域:含特殊标记的成绩统计
班级50名学生中,3人“缺考”、2人“作弊”(均为文本)。用STDEVPA计算时,这些数据按0参与运算,结果能真实反映整体成绩离散度。若误用STDEVP忽略这些数据,可能掩盖成绩分化问题。
(3)质量检测与市场调研
工厂质检中,“不合格”“待复检”等文本可通过STDEVPA按0纳入计算,避免因忽略不良品导致的质量误判;市场调研时,“未评价”文本和“推荐”逻辑值也能被合理转换,确保用户反馈分析的完整性。
四、避坑指南与高效联用技巧
(1)常见误区
不要期待函数“智能识别文本含义”:“优秀”“良好”等文本会被统一视为0,需提前用IF函数转换(如“=IF(A1="优秀",90,A1)”);
区分空白单元格与文本:空白不参与计算,文本(包括空格)按0计算;
仅用于总体数据:样本数据(如从1000人中抽取50人)需改用STDEVA函数。
(2)函数联用
与IF函数组合:可自定义转换规则,例如“=STDEVPA(IF(A1:A100="未考核",60,A1:A100))”将“未考核”按60分计算(输入后按Ctrl+Shift+Enter确认数组公式);
与AVERAGEPA搭配:前者看离散程度,后者看集中趋势,两者结合能全面描述数据特征。
结语
STDEVPA函数的核心价值,在于让含文本、逻辑值的总体数据得到完整统计。使用时需明确数据性质——只要存在非数值标记,就优先选择STDEVPA;同时注意非数值数据的转换规则,必要时结合IF函数自定义处理。掌握这个工具,复杂数据的离散分析会变得精准又高效,让你的统计结论更具参考价值。








评论 (0)