
在数据统计中,表格里常混杂“未填写”“待确认”等文本,或是“是/否”“通过/未通过”等逻辑值,用常规函数计算易让结果失真,而WPS的STDEVA函数能高效处理这类夹杂文本的数据;不仅如此,面对包含文本或逻辑值的样本分析,STDEVA函数也能凭借其特性规避计算偏差;可以说,有了STDEVA函数,这类特殊数据的统计才能更精准,样本分析结果也更可靠。
一、STDEVA与STDEV.S的核心区别
STDEVA可以理解为STDEV.S的“增强版”,两者的核心差异在于对非数值数据的处理:
- STDEV.S会直接忽略文本、逻辑值等非数值数据,导致样本量减少;
- STDEVA会按规则转换非数值数据后参与计算:文本视为0,TRUE视为1,FALSE视为0(空白单元格仍会被忽略)。
比如某公司20名员工的考核得分中,有3个“请假”和2个“未达标”。用STDEV.S计算时,这5个非数值会被忽略,相当于只分析15人;而STDEVA会将它们转为0参与计算,20个样本全部生效,结果更贴合实际。
二、STDEVA函数的基础用法
- 基本语法
STDEVA(value1,[value2],...)
value1:必需参数,可是数值、文本、逻辑值、单元格引用等;
[value2],...:可选参数,最多254个,用法同value1。
- 实操步骤
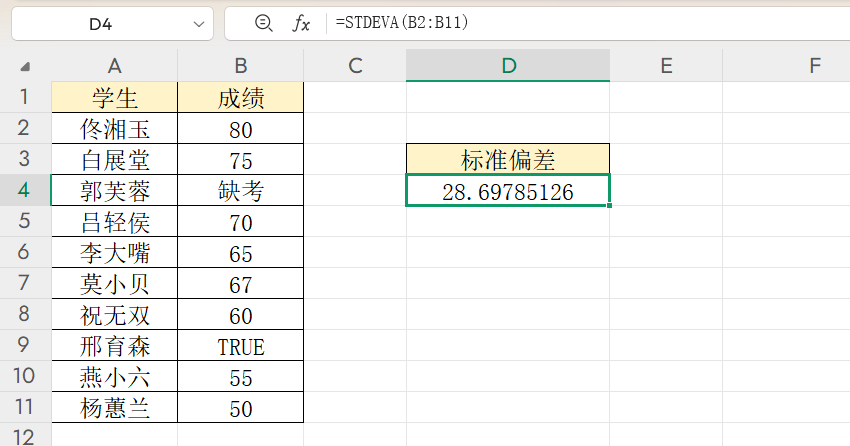
以10名学生的数学成绩为例(含“缺考”文本和TRUE逻辑值):
选中显示结果的单元格;
输入公式:=STDEVA(B2:B11);
此时“缺考”按0计算,TRUE按1计算,10个样本全部参与运算。
三、实战场景与避坑指南
适用场景
- 教育领域:处理含“缺考”“缓考”的成绩,避免样本量减少;
- 市场调研:将“未评价”按0计入满意度分析,反映潜在态度;
- 人事管理:把“事假”转为0统计出勤波动,更真实体现团队状态。
常见误区
- 误区1:认为能将“优秀”“良好”转换为对应数值(实际所有文本均视为0);
- 误区2:混淆空白单元格和“空白”文本(前者被忽略,后者按0计算);
- 误区3:纯数值数据中使用(结果与STDEV.S一致,但运算效率更低)。
四、函数联用技巧
- 与IF函数组合:自定义转换规则(如“缓考”按平均分计算);
- 与COUNTBLANK配合:检查空白单元格占比(超过20%需手动补全);
- 与STDEV.S对比:通过差值判断非数值数据的影响程度。
结语
STDEVA函数的核心价值,在于让“不完美”数据也能参与标准差计算,尤其适合快速分析含文本、逻辑值的样本。使用时需注意:非数值数据适合视为0、占比不超过30%、且符合业务场景逻辑。下次遇到混有特殊值的数据,不妨试试STDEVA,让数据分析更高效、更精准。







评论 (0)